You may have noticed, but I created this blog site using Pelican, and host it as a static site on AWS. Here's how I did it, step by step.
AWS STUFF FIRST:
create a bucket
Create the S3 bucket that will contain your static site.
It is very important that you name the bucket the same as what you want your site DNS to be. For example, since my DNS was to be sean.town, I named my bucket sean.town:
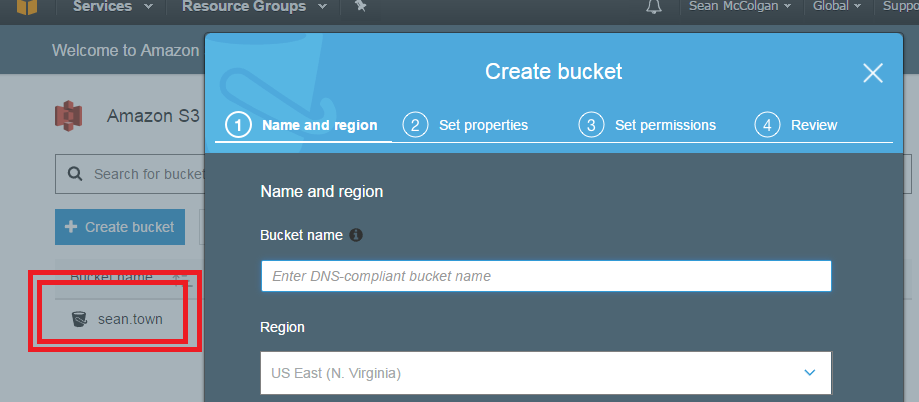
If you want your bucket to be mycoolsite.com, name it mycoolsite.com
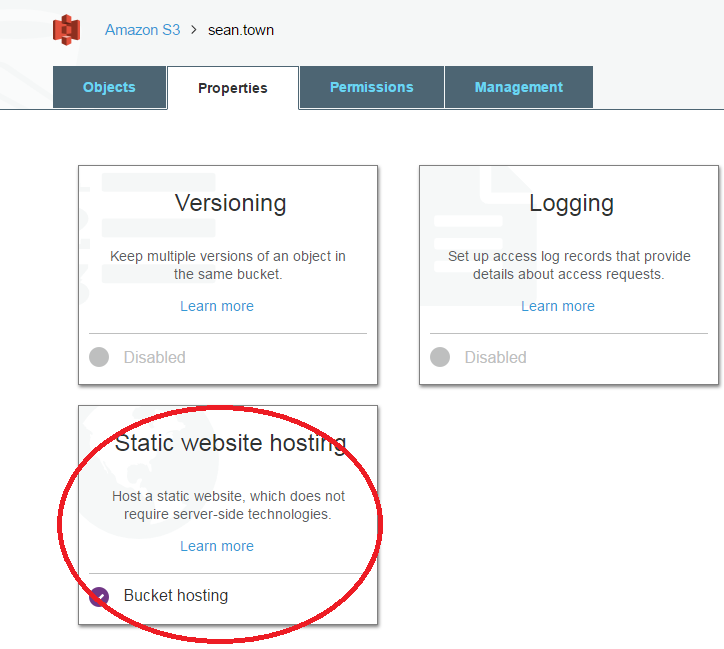
You also want to make your bucket public by going to your bucket properties and selecting static S3 site:
get a domain
snagged the sean.town domain using AWS's Route 53 service. This process is pretty straightforward, they talk you through a couple menus and you select the domain you want to purchase.
set up your hosted zone
This is where we tie your DNS record to the S3 bucket. Pretty simple, but not exactly straightforward.
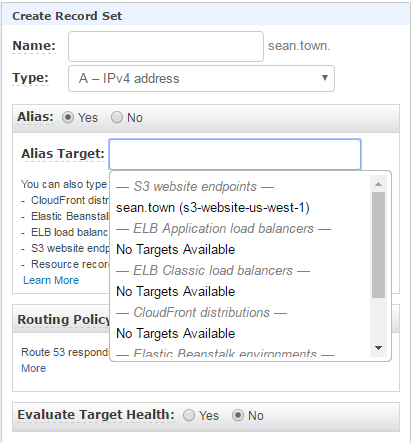
When you're creating the hosted zone for your S3 bucket, be sure to select 'Alias: Yes', and then you can find your S3 bucket from the dropdown when you go to select the Alias Target. if you did not name your bucket after your DNS record, it will not show up here:
Pelican
Now, how do I get a static blog site? I'm using windows, but the process will be similar in other operating systems. You're gonna need Python:
When it's installed, you can pop into a shell and use pip install pelican to get pelican. I suggest using a virtualenv for every python project (like this blog), but that's a whole separate topic: vitual environments
From that point, it's pretty simple, I just followed the quickstart docs, and run pelican content to generate my site. What's next?
upload generated site to S3
This is the fun part, simply upload all the contents of the output folder that is created when you ran pelican content. Now when you go to your domain, you should see your blog site! Nice!
improvements (to be continued)
This is pretty sweet and it works, but for the next installment, I think it would be better to have a more streamlined workflow. Also, what happens if I delete my blog content by accident?
That's right, we're gonna want to use git, github and perhaps some more automated, hands-off ways of deploying this blog.
Why git and github?
I want git because it's a powerful version control system. If I don't like the way a blogpost turned out, and I want to revert to an earlier state, or I want to change some things around, this is the best way to do it.
I want github because it allows me to host my git project somewhere other than my local machine. This means that if my computer crashes and I lose everything, I can still download my git project from github onto a new machine and go right back to where I left off. Think of it as backups. It does a lot of other stuff too, but we don't need that for a personal blog site.
What about automation?
I'm thinking of using some post push git hooks for kicking off some simple script that runs pelican content then uploads the output folder using something like tinys3. This way I don't have to manually upload every time. When I push to github, it deploys to S3 for me.